本文主题:
Informer机制架构设计总览
Reflector理解
DeltaFIFO理解
Indexer理解
如果涉及到资源的内容,本文以Deployment资源进行相关内容讲述。
Informer机制架构设计总览
下面是我根据理解画的一个数据流转图,从全局视角看一下数据的整体走向是怎么样的。
其中虚线的表示的是代码中的方法。
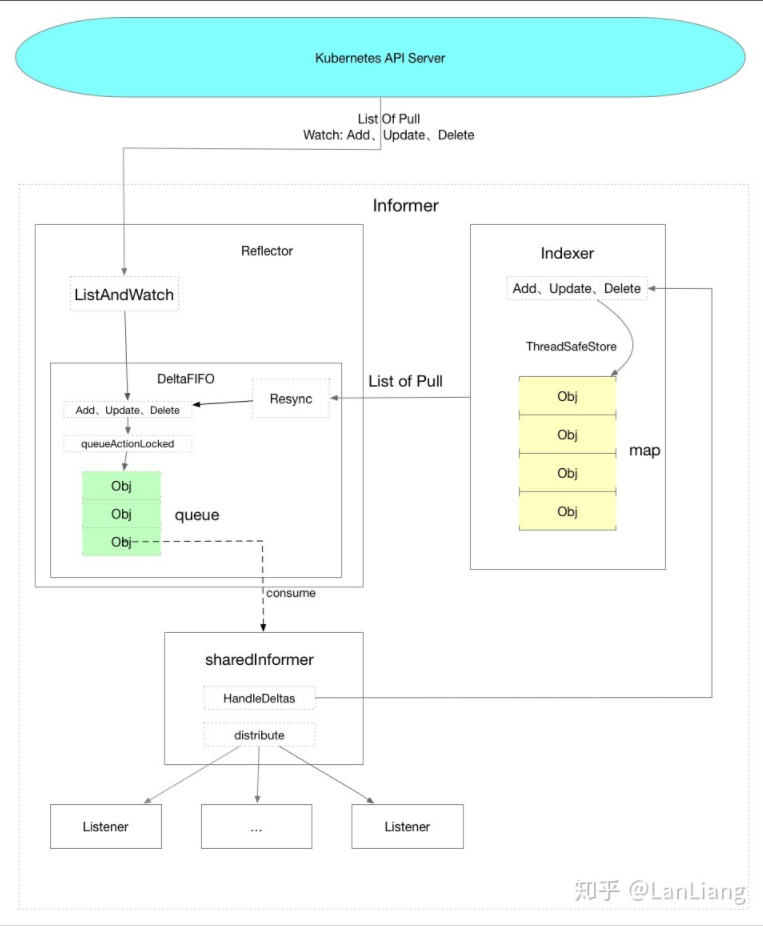
首先讲一个结论:
通过Informer机制获取数据的情况下,在初始化的时候会从Kubernetes API Server获取对应Resource的全部Object,后续只会通过Watch机制接收API Server推送过来的数据,不会再主动从API Server拉取数据,直接使用本地缓存中的数据以减少API Server的压力。
Watch机制基于HTTP的Chunk实现,维护一个长连接,这是一个优化点,减少请求的数据量。第二个优化点是SharedInformer,它可以让同一种资源使用的是同一个Informer,例如v1版本的Deployment和v1beta1版本的Deployment同时存在的时候,共享一个Informer。
上面图中可以看到Informer分为三个部分,可以理解为三大逻辑。
其中Reflector主要是把从API Server数据获取到的数据放到DeltaFIFO队列中,充当生产者角色。
SharedInformer主要是从DeltaFIFIO队列中获取数据并分发数据,充当消费者角色。
最后Indexer是作为本地缓存的存储组件存在。
Reflector理解
Reflector中主要看Run、ListAndWatch、watchHandler三个地方就足够了。
源码位置是 tools/cache/reflector.go
// Ruvn starts a watch and handles watch events. Will restart the watch if it is closed.
// Run will exit when stopCh is closed.
//开始时执行Run,上一层调用的地方是 controller.go中的Run方法
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(3).Infof("Starting reflector %v (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.Until(func() {
//启动后执行一次ListAndWatch
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
...
// and then use the resource version to watch.
// It returns error if ListAndWatch didn't even try to initialize watch.
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
...
// Attempt to gather list in chunks, if supported by listerWatcher, if not, the first
// list request will return the full response.
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
//这里是调用了各个资源中的ListFunc函数,例如如果v1版本的Deployment
//则调用的是informers/apps/v1/deployment.go中的ListFunc
return r.listerWatcher.List(opts)
}))
if r.WatchListPageSize != 0 {
pager.Pa1geSize = r.WatchListPageSize
}
// Pager falls back to full list if paginated list calls fail due to an "Expired" error.
list, err = pager.List(context.Background(), options)
close(listCh)
...
//这一部分主要是从API SERVER请求一次数据 获取资源的全部Object
if err != nil {
return fmt.Errorf("%s: Failed to list %v: %v", r.name, r.expectedTypeName, err)
}
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(li
st)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v: %v", r.name, list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("%s: Unable to understand list result %#v (%v)", r.name, list, err)
}
initTrace.Step("Objects extracted")
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("%s: Unable to sync list result: %v", r.name, err)
}
initTrace.Step("SyncWith done")
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
...
//处理Watch中的数据并且将数据放置到DeltaFIFO当中
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case apierrs.IsResourceExpired(err):
klog.V(4).Infof("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil
}
...
}
数据的生产就结束了,就两点:
初始化时从API Server请求数据
监听后续从Watch推送来的数据
DeltaFIFO理解
先看一下数据结构:
type DeltaFIFO struct {
...
items map[string]Deltas
queue []string
...
}
type Delta struct {
Type DeltaType
Object interface{}
}
type Deltas []Delta
type DeltaType string
// Change type definition
const (
Added DeltaType = "Added"
Updated DeltaType = "Updated"
Deleted DeltaType = "Deleted"
Sync DeltaType = "Sync"
)
其中queue存储的是Object的id,而items存储的是以ObjectID为key的这个Object的事件列表,
可以想象到是这样的一个数据结构,左边是Key,右边是一个数组对象,其中每个元素都是由type和obj组成.

DeltaFIFO顾名思义存放Delta数据的先入先出队列,相当于一个数据的中转站,将数据从一个地方转移另一个地方。
主要看的内容是queueActionLocked、Pop、Resync
queueActionLocked方法:
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
...
newDeltas := append(f.items[id], Delta{actionType, obj})
//去重处理
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
...
//pop消息
f.cond.Broadcast()
...
return nil
}
Pop方法:
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
//阻塞 直到调用了f.cond.Broadcast()
f.cond.Wait()
}
//取出第一个元素
id := f.queue[0]
f.queue = f.queue[1:]
...
item, ok := f.items[id]
...
delete(f.items, id)
//这个process可以在controller.go中的processLoop()找到
//初始化是在shared_informer.go的Run
//最终执行到shared_informer.go的HandleDeltas方法
err := process(item)
//如果处理出错了重新放回队列中
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
...
}
}
Resync机制:
小总结:每次从本地缓存Indexer中获取数据重新放到DeltaFIFO中执行任务逻辑。
启动的Resync地方是reflector.go的resyncChan()方法,在reflector.go的ListAndWatch方法中的调用开始定时执行。
go func() {
//启动定时任务
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
//定时执行 调用会执行到delta_fifo.go的Resync()方法
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
func (f *DeltaFIFO) Resync() error {
...
//从缓存中获取到所有的key
keys := f.knownObjects.ListKeys()
for _, k := range keys {
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
func (f *DeltaFIFO) syncKeyLocked(key string) error {
//获缓存拿到对应的Object
obj, exists, err := f.knownObjects.GetByKey(key)
...
//放入到队列中执行任务逻辑
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
return nil
}
SharedInformer消费消息理解
主要看HandleDeltas方法就好,消费消息然后分发数据并且存储数据到缓存的地方
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
...
//查一下是否在Indexer缓存中 如果在缓存中就更新缓存中的对象
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
//把数据分发到Listener
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
//没有在Indexer缓存中 把对象插入到缓存中
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
...
}
}
return nil
}
Indexer理解
这块不会讲述太多内容,因为我认为Informer机制最主要的还是前面数据的流转,当然这并不代表数据存储不重要,而是先理清楚整体的思路,后续再详细更新存储的部分。
Indexer使用的是threadsafe_store.go中的threadSafeMap存储数据,是一个线程安全并且带有索引功能的map,数据只会存放在内存中,每次涉及操作都会进行加锁。
// threadSafeMap implements ThreadSafeStore
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
indexers Indexers
indices Indices
}
Indexer还有一个索引相关的内容就暂时不展开讲述。
Example代码
package main
import (
"flag"
"fmt"
"path/filepath"
"time"
v1 "k8s.io/api/apps/v1"
"k8s.io/apimachinery/pkg/labels"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
)
func main() {
var err error
var config *rest.Config
var kubeconfig *string
if home := homedir.HomeDir(); home != "" {
kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "[可选] kubeconfig 绝对路径")
} else {
kubeconfig = flag.String("kubeconfig", filepath.Join("/tmp", "config"), "kubeconfig 绝对路径")
}
// 初始化 rest.Config 对象
if config, err = rest.InClusterConfig(); err != nil {
if config, err = clientcmd.BuildConfigFromFlags("", *kubeconfig); err != nil {
panic(err.Error())
}
}
// 创建 Clientset 对象
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err.Error())
}
// 初始化一个 SharedInformerFactory 设置resync为60秒一次,会触发UpdateFunc
informerFactory := informers.NewSharedInformerFactory(clientset, time.Second*60)
// 对 Deployment 监听
//这里如果获取v1betav1的deployment的资源
// informerFactory.Apps().V1beta1().Deployments()
deployInformer := informerFactory.Apps().V1().Deployments()
// 创建 Informer(相当于注册到工厂中去,这样下面启动的时候就会去 List & Watch 对应的资源)
informer := deployInformer.Informer()
// 创建 deployment的 Lister
deployLister := deployInformer.Lister()
// 注册事件处理程序 处理事件数据
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: onAdd,
UpdateFunc: onUpdate,
DeleteFunc: onDelete,
})
stopper := make(chan struct{})
defer close(stopper)
informerFactory.Start(stopper)
informerFactory.WaitForCacheSync(stopper)
// 从本地缓存中获取 default 命名空间中的所有 deployment 列表
deployments, err := deployLister.Deployments("default").List(labels.Everything())
if err != nil {
panic(err)
}
for idx, deploy := range deployments {
fmt.Printf("%d -> %s\n", idx+1, deploy.Name)
}
<-stopper
}
func onAdd(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("add a deployment:", deploy.Name)
}
func onUpdate(old, new interface{}) {
oldDeploy := old.(*v1.Deployment)
newDeploy := new.(*v1.Deployment)
fmt.Println("update deployment:", oldDeploy.Name, newDeploy.Name)
}
func onDelete(obj interface{}) {
deploy := obj.(*v1.Deployment)
fmt.Println("delete a deployment:", deploy.Name)
}
以上示例代码中程序启动后会拉取一次Deployment数据,并且拉取数据完成后从本地缓存中List一次default命名空间的Deployment资源并打印,然后每60秒Resync一次Deployment资源。
QA
为什么需要Resync?
在本周有同学提出一个,我看到这个问题后也感觉挺奇怪的,因为Resync是从本地缓存的数据缓存到本地缓存(从开始到结束来说是这样),为什么需要把数据拿出来又走一遍流程呢?当时钻牛角尖也是想不明白,后来换个角度想就知道了。
数据从API Server过来并且经过处理后放到缓存中,但数据并不一定就可以正常处理,也就是说可能报错了,而这个Resync相当于一个重试的机制。
可以尝试实践一下: 部署有状态服务,存储使用LocalPV(也可以换成自己熟悉的),这时候pod会由于存储目录不存在而启动失败. 然后在pod启动失败后再创建好对应的目录,过一会pod就启动成功了。 这是我理解的一种情况。
总结:
Informer机制在K8S中是各个组件通讯的基石,理解透彻是非常有益的,我也还在进一步理解的过程中,欢迎一起交流。